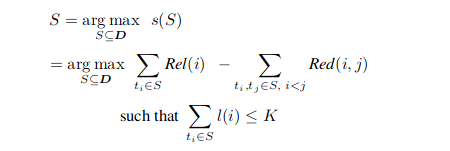Traitement de données massives
John Samuel
CPE Lyon
Year: 2020-2021
Email: john(dot)samuel(at)cpe(dot)fr

John Samuel
CPE Lyon
Year: 2020-2021
Email: john(dot)samuel(at)cpe(dot)fr






.jpg)



.png)


Soit